نحوه کلاستر کردن indexer ها در اسپلانک

index در اصل مخزن دادههای Splunk میباشد. اسپلانک دادههای دریافتی را به رویدادهایی (Events) تبدیل و آنها را در index ها ذخیره میکند. یک indexer، یک کامپوننت از اسپلانک میباشد که کار ایندکسینگ دادههای دریافتی را انجام میدهد. در یک پیادهسازی اسپلانک با مقیاس کوچک یک indxer همه وظایف Splunk از جمله مدیریت جستجو و دادههای وردی را نیز انجام میدهد. اما در پیادهسازیهای توزیع شده وظایف دریافت ورودیها و مدیریت جستجوها به سایر کامپوننتها واگذار میشود. یک indexer cluster گروهی از indexer هاست که برای تکثیر دیتای سایر indexer ها در کلاستر تنظیم شدهاند. در این صورت سیستم چندین کپی از دادهها را به صورت همزمان نگهداری میکند. این فرآیند به index replication یا indexer clustering معروف است. در واقع کلاستر با نگهداری چندین کپی از index ها علاوه بر جلوگیری از Data loss، میزان در دسترس بودن دادهها برای جستجو را نیز بالا میبرد.
index ها
به محض اینکه اسپلانک دادههای دریافتی را پردازش میکند، آنها را به index ها اضافه مینماید. اسپلانک به صورت پیشفرض به همراه تعدادی Index ارائه میشود که میتوانیم در صورت نیاز index هایی را نیز اضافه کنیم.
یک index در اسپلانک شامل تعدادمتنوعی از فایلها میباشد. این فایلها به دو دسته اصلی تقسیم میشود.
- دیتای خام در فرمت فشرده (raw data).
- index ها که به دیتای خام اشاره دارند. (فایلهای مربوط به index ها که به tsidx نیز معروفند.)
فایل ایندکس سری زمانی (time-series index file) که فایل شاخص نیز نامیده میشود. هر کلمه کلیدی منحصربهفرد در دادهها را با ارجاعات مکانی مربوط به رویدادها مرتبط میکند و در یک فایل، همراه rawdata ذخیره میکند. در اسپلانک فایل مربوط به rawdata و فایلهای tsidx مرتبط با آن، محتویات یک Bucket را تشکیل میدهند.
هر جستجویی که انجام میدهیم، ماژول جستجو فایلهای tsidx را برای پیدا کردن “کلمات کلیدی جستجو” اسکن و از ارجاعات مکان آنها برای بازیابی رویدادهایی مرتبط با آن کلمات کلیدی از فایل rawdata استفاده میکند. اسپلانک همچنین برای سرعت بخشیدن به جستجوها، از فیلترهای bloom برای محدود کردن مجموعه فایلهای tsidx که باید برای رسیدن به نتایج دقیقتر جستجو شوند، استفاده میکند. نکته دیگر اینکه اسپلانک همه چیز را از طریق فایلها و به صورت Flatمدیریت میکند و نیازی به دیتابیس ندارد.

پردازش رویدادها
در طول index کردن دادهها، Splunk کار پردازش رویدادها را نیز انجام میدهد. اسپلانک در واقع دادههای دریافتی را پردازش میکند تا امکان جستجو و تجزیه و تحلیل سریع را فراهم کند. در این فرآیند نتایج حاصل از پردازش در فهرستی با عنوان رویداد ذخیره میشود. بنابراین اسپلانک در حین ایندکس کردن، میتواند دادهها را به روشهای مختلفی بهینهسازی و بهبود دهد.
- جداسازی جریان داده به رویدادهای مستقل و قابل جستجو.
- ایجاد یا شناسایی مهرهای زمانی (Timestamp).
- استخراج فیلدهایی مانند host، منبع (source) و نوع منبع (source type).
- انجام اقدامات تعریف شده توسط کاربر بر روی دادههای ورودی. ازجمله شناسایی فیلدهای سفارشی، پوشاندن دادههای حساس (Data masking)، نوشتن کلیدهای جدید یا اصلاح شده، اعمال قوانین شکستن برای رویدادهای چند خطی، فیلتر کردن رویدادهای ناخواسته، و هدایت رویدادها به index ها یا سرورهای مشخص.
ایندکسرها (indexers)
indexer مهمترین کامپوننت اسپلانک میباشد که وظیفه ایجاد و مدیریت index ها را برعهده دارد. هر ایندکسر دو وظیفه اصلی را برعهده دارد.
- ایندکس کردن دادههای ورودی.
- جستجو کردن دادههای ایندکس شده.
یک استقرار تک ماشینی که فقط از یک Splunk استفاده میکند، ایندکسر هم کار کنترل ورودی داده و هم مدیریت جستجو را انجام میدهد.
اما در مقیاس بزرگتر، کار ایندکسینگ از کار ورودی داده و گاهی اوقات از کار مدیریت جستجو نیز جدا میشود. در استقرارهای بزرگتر و توزیع شده، ایندکسر بایستی بر روی ماشین خود قرار داشته باشد و تنها کار indexing را به همراه جستجوی دادههای ایندکس شده خود انجام دهد. سایر اجزا در این نوع پیادهسازی، نقشهایی به غیر از ایندسینگ را بر عهده می گیرند. در واقع در یک پیادهسازی توزیع شده فورواردرها دادهها را ارسال، ایندکسرها دادهها را فهرست و جستجو میکنند، و search head ها، جستجوها را در سراسر مجموعه ایندکسرها هماهنگ میکنند. عکس زیر یک نمونه از یک استقرار توزیع شده را نشان میدهد.

indexer cluster
یک کلاستر ایندکسر، گروهی از node های اسپلانک است که به صورت هماهنگ با هم کار میکنند و قابلیتهای indexing و جستجو را به صورت افزونه ارائه میدهند. در این نوع پیادهسازی سه نوع نود قرار میگیرد.
- نود manager برای مدیریت کلاستر.
- نودهای peer که نقش ایندکسینگ، نگهداری از چندین کپی از دادهها و جستجو در دادههای ذخیره شده در کلاستر را انجام میدهند.
- یک یا چند کامپوننت search head برای انجام جستجو در همه peer نودها.
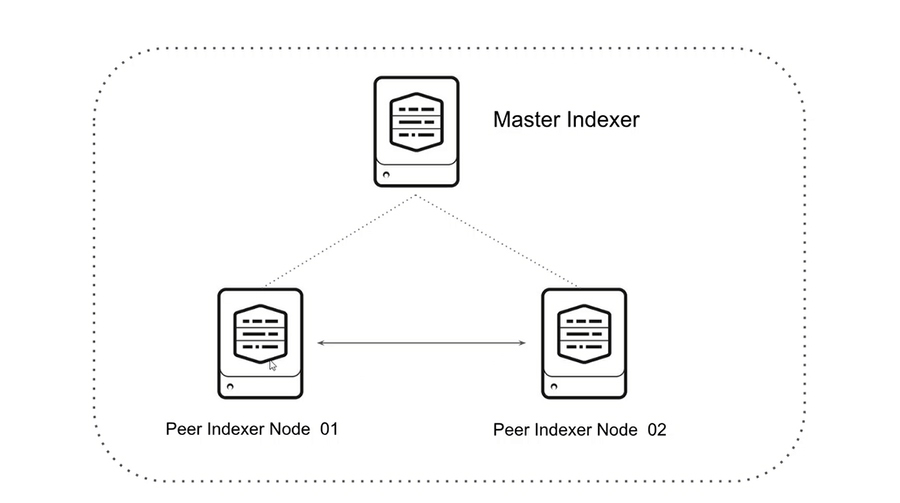
براساس شکل بالا برای راه اندازی Cluster indexer به یک Master node و دو Peer node نیاز داریم. بااستفاده از دستورات زیر نودهای مورد نیاز را بر روی داکر راه اندازی میکنیم.
docker run --name splunk-midx01 -h splunk-midx01 -d -p 8000:8000 -e SPLUNK_START_ARGS=--accept-license -e SPLUNK_PASSWORD=password splunk/splunk:latest
docker run --name splunk-idx1 -h splunk-idx1 -d -p 8001:8000 -e SPLUNK_START_ARGS=--accept-license -e SPLUNK_PASSWORD=password splunk/splunk:latest
docker run --name splunk-idx2 -h splunk-idx2 -d -p 8002:8000 -e SPLUNK_START_ARGS=--accept-license -e SPLUNK_PASSWORD=password splunk/splunk:latest
تنظیمات مربوط به indexer master node
برای انجام تنظیمات indexer master node مراحل زیر را انجام میدهیم.
- ابتدا از مسیر setting، گزینه ndexer clustering را انتخاب میکنیم.
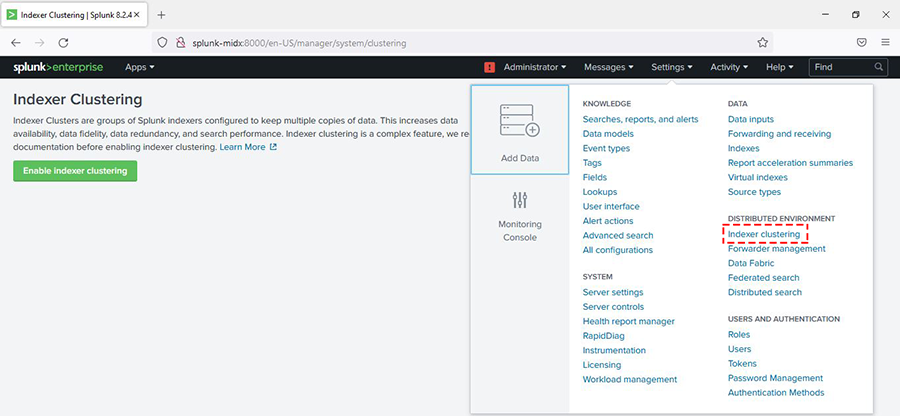
- بعد از زدن گزینه enable indexer clustering گزینه master node را انتخاب و دکمه next را میزنیم.

- در صفحه بعدی تعداد peer node ها و تعداد کپیهای داده که قابل جستجو باشند را مشخص میکنیم.

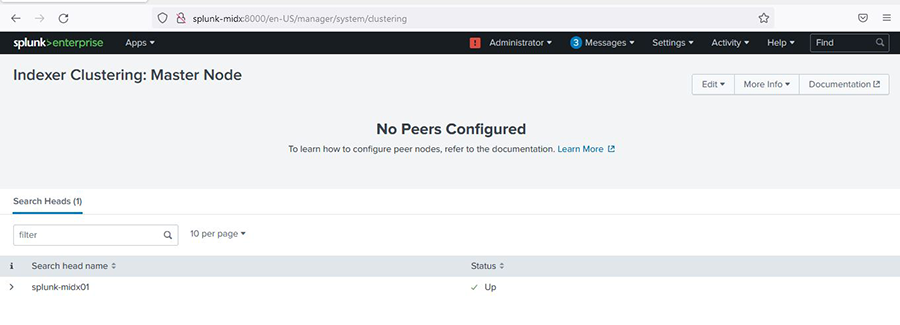
در ادامه نود master به صورت زیر اضافه میشود.
تنظیمات مربوط به peer node ها
برای انجام تنظیمات indexer ها همانند تنظیمات master node از قسمت setting گزینه indexer clustering را زده و در صفحه مربوط به enable clustering گزینه peer node را انتخاب میکنیم. در ادامه اطلاعات مربوط به نود master را همانند شکل زیر وارد کرده و دکمه enable peer node را میزنیم.

در صورتی که تنظیمات به درستی انجام شده باشد نودهای مربوط به indexer ها بر روی نود master همانند شکل زیر در قسمت indexer clustering اضافه میشود.

مطالب زیر را حتما مطالعه کنید

نحوه انجام تنظیمات Device Failover و link Failover بر روی فایروال سیسکو ASA

اتوماتیک کردن فرآیندهای امنیتی با استفاده از Ansible

نحوه بررسی بدافزار با استفاده از Splunk و Sysmon

نحوه ارسال لاگ به indexer cluster

نحوه راه اندازی High Availability/Clustering در لینوکس
